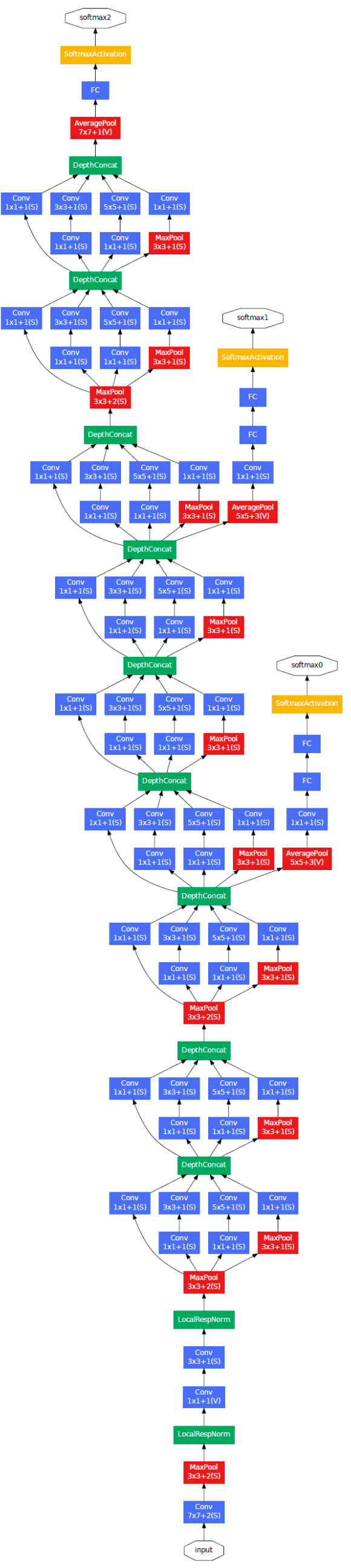
GoogLeNet
学习了论文Going deeper with convolutions,尝试进一步推导其模型,并使用PyTorch实现该网络
Inception模块
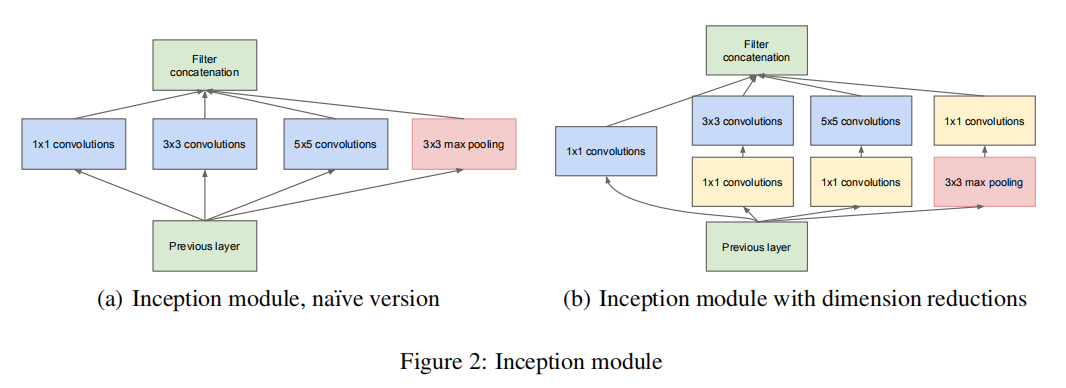
Inception模块是GoogLeNet有别于之前网络架构的最重要的地方。从某种意义上来说,Inception模块并没有创造新的网络层,它只是在同一层中并行执行多个独立的卷积操作(\(1\times 1, 3\times 3, 5\times 5\)),这些卷积操作后的输出数据体拥有相同大小的空间尺寸,可以基于深度维度进行连接,再输出到下一层
在\(3\times 3\)和\(5\times 5\)卷积核操作前以及max pooling操作后执行\(1\times 1\)大小卷积操作,通过控制滤波器个数来减少输出数据体深度,从而实现数据降维的目的,还能够通过激活函数提高卷积表达能力
Inception模块的实现具有如下几个优点:
- 允许在每个阶段显著增加单元的数量,而不会导致计算复杂性的失控膨胀
- 该操作与计算直觉一致,即视觉信息应该在不同的尺度上进行处理,然后进行汇总,以便下一阶段可以同时从不同的尺度提取特征
参数解析
论文中以表格方式给出了GoogLeNet的参数设置
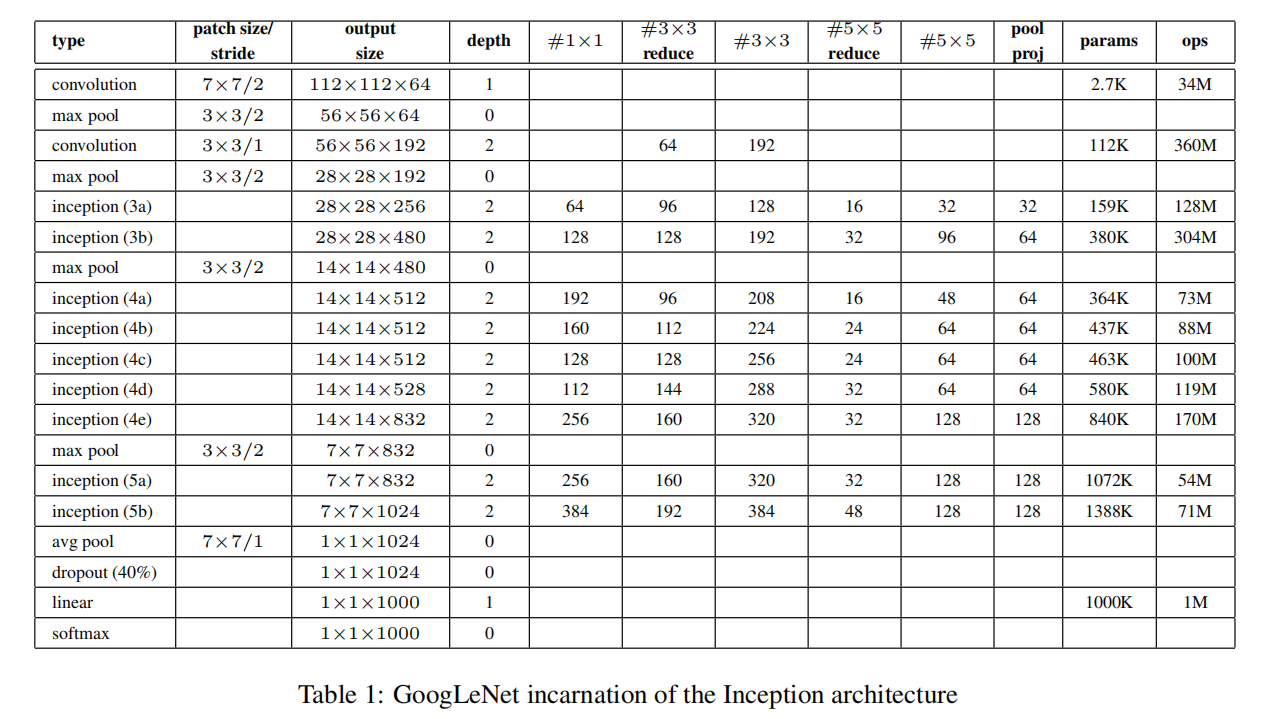
不过里面并没有很详细的列出各层参数,比如padding,下面从头开始推导一遍。假定输入大小为\(N\times C\times H\times W = 128\times 3\times 224\times 224\),其各层计算如下:
convolution
- 输入数据体:\(128\times 3\times 224\times 224\)
- 卷积核大小为\(7\times 7\),步长为\(2\),零填充为\(3\)
- 滤波器个数:\(64\)
- 输出数据体:\(128\times 64\times 112\times 112\)
max pool
- 输入数据体:\(128\times 64\times 112\times 112\)
- 卷积核大小为\(3\times 3\),步长为\(2\),零填充为\(1\)
- 输出数据体:\(128\times 64\times 56\times 56\)
convolution
先执行\(1\times 1\)大小卷积操作
- 输入数据体:\(128\times 64\times 56\times 56\)
- 卷积核大小为\(1\times 1\),步长为\(1\),零填充为\(0\)
- 滤波器个数:\(64\)
- 输出数据体:\(128\times 64\times 56\times 56\)
再执行\(3\times 3\)大小卷积操作
- 输入数据体:\(128\times 64\times 56\times 56\)
- 卷积核大小为\(3\times 3\),步长为\(1\),零填充为\(1\)
- 滤波器个数:\(192\)
- 输出数据体:\(128\times 192\times 56\times 56\)
max pool
- 输入数据体:\(128\times 192\times 56\times 56\)
- 卷积核大小为\(3\times 3\),步长为\(2\),零填充为\(1\)
- 输出数据体:\(128\times 192\times 28\times 28\)
inception (3a)
1x1
- 输入数据体:\(128\times 192\times 28\times 28\)
- 卷积核大小为\(1\times 1\),步长为\(1\),零填充为\(0\)
- 滤波器个数:\(64\)
- 输出数据体:\(128\times 64\times 28\times 28\)
3x3
先执行\(1\times 1\)大小卷积操作
- 输入数据体:\(128\times 192\times 28\times 28\)
- 卷积核大小为\(1\times 1\),步长为\(1\),零填充为\(0\)
- 滤波器个数:\(96\)
- 输出数据体:\(128\times 96\times 28\times 28\)
再执行\(3\times 3\)大小卷积操作
- 输入数据体:\(128\times 96\times 28\times 28\)
- 卷积核大小为\(3\times 3\),步长为\(1\),零填充为\(1\)
- 滤波器个数:\(128\)
- 输出数据体:\(128\times 128\times 28\times 28\)
5x5
先执行\(1\times 1\)大小卷积操作
- 输入数据体:\(128\times 192\times 28\times 28\)
- 卷积核大小为\(1\times 1\),步长为\(1\),零填充为\(0\)
- 滤波器个数:\(16\)
- 输出数据体:\(128\times 16\times 28\times 28\)
再执行\(3\times 3\)大小卷积操作
- 输入数据体:\(128\times 16\times 28\times 28\)
- 卷积核大小为\(5\times 5\),步长为\(1\),零填充为\(2\)
- 滤波器个数:\(32\)
- 输出数据体:\(128\times 32\times 28\times 28\)
max pooling
先执行\(Max Pooling\)操作
- 输入数据体:\(128\times 192\times 28\times 28\)
- 卷积核大小为\(3\times 3\),步长为\(1\),零填充为\(1\)
- 输出数据体:\(128\times 192\times 28\times 28\)
再执行\(1\times 1\)大小卷积操作
- 输入数据体:\(128\times 192\times 28\times 28\)
- 卷积核大小为\(1\times 1\),步长为\(1\),零填充为\(0\)
- 滤波器个数:\(32\)
- 输出数据体:\(128\times 32\times 28\times 28\)
连接
上述4个子模块计算得到了相同的空间尺寸的输出书具体,然后按深度通道进行连接,最后得到\(128\times 256\times 28\times 28\)大小的输出数据体
后续操作
后续网络层的实现和上述操作类似
PyTorch
PyTorch 1.4提供了GoogleNet-v3模型实现 - vision/torchvision/models/googlenet.py,参考其实现自定义GoogLeNet
Note:完整实现参考zjZSTU/GoogLeNet
首先定义3个子类,分别用于实现卷积层、Inception模块以及辅助分类器
BasicConv2dInceptionInceptionAux
Note:对于GoogLeNet中的MaxPooling层,其需要额外设置padding=1,在PyTorch GoogLeNet-v3实现中,通过设置ceil_mode=True得到预计的输出尺寸
BasicConv2d
用于封装卷积层操作,以便网络的进一步调整(比如,添加批量归一化层)
1 | class BasicConv2d(nn.Module): |
Inception
对于每个Inception模块,需要输入
- \(1\times 1\)大小滤波器个数
- \(3\times 3\)大小滤波器个数以及作用于其之前的\(1\times 1\)大小滤波器个数
- \(5\times 5\)大小滤波器个数以及作用于其之前的\(1\times 1\)大小滤波器个数
- 作用于
Max Pooling之后的\(1\times 1\)大小滤波器个数
1 | class Inception(nn.Module): |
InceptionAux
辅助分类器在Inception (4a)得到的输入大小是\(14\times 14\times 512\),在Inception (4d)得到的输入大小是\(14\times 14\times 528\)
- 首先使用全局平均池化操作(滤波器大小为\(5\times 5\),步长为\(3\)),保证输出数据体的空间尺寸为\(4\times 4\)
- 使用
128个\(1\times 1\)大小卷积滤波器,用于维度衰减和整流线性激活。此时输出数据体大小为\(4\times 4\times 128\) - 使用
1024个滤波器的全连接层 - 随机失活层:失活概率
70% softmax分类器,用于分类1000类
1 | class InceptionAux(nn.Module): |
GoogLeNet
结合上述3个子类,实现GoogLeNet网络
1 | class GoogLeNet(nn.Module): |
测试
比较GoogLeNet与AlexNet.具体测试代码参考test_googlenet.py
参数个数
1 | [alexnet] param num: 61100840 |
AlexNet有6千万个参数,GoogLeNet仅有1337万个,两者相差4.57倍
测试时间
1 | [alexnet] time: 0.0193 |
计算100次测试图像平均使用时间:
AlexNet:0.0252秒GoogLeNet:0.0764秒
两者相差近3倍的计算时间
训练一
训练GoogLeNet模型,训练参数如下:
- 数据集:
PASCAL VOC 07+12,20类共40058个训练样本和12032个测试样本 - 批量大小:
128 - 优化器:
Adam,学习率为1e-3 - 随步长衰减:每隔
8轮衰减4%,学习因子为0.96 - 迭代次数:
100轮
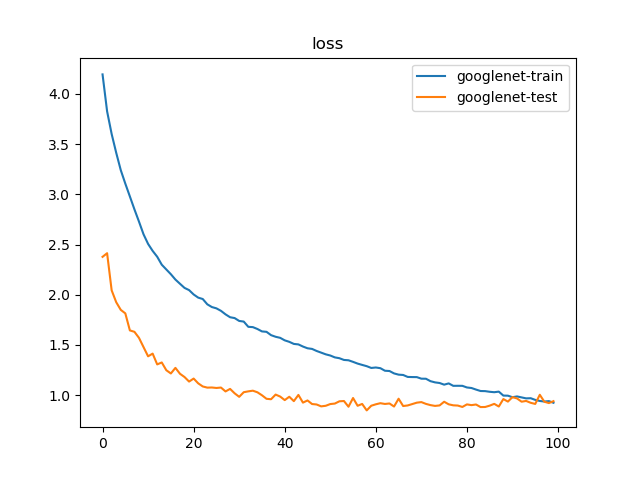
训练100次结果如下:
1 | {'train': 40058, 'test': 12032} |
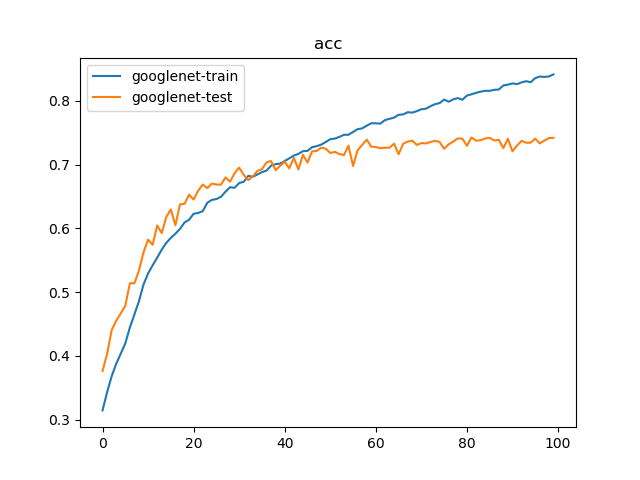
训练二
比对GoogLeNet和AlexNet训练,训练参数如下:
- 数据集:
PASCAL VOC 07+12,20类共40058个训练样本和12032个测试样本 - 批量大小:
128 - 优化器:
Adam,学习率为1e-3 - 随步长衰减:每隔
4轮衰减10%,学习因子为0.9 - 迭代次数:
100轮
训练100次结果如下:
1 | {'train': 40058, 'test': 12032} |
100轮迭代后,GoogLeNet实现了74.23%的最好测试精度,AlexNet实现了70.37%的最好测试精度
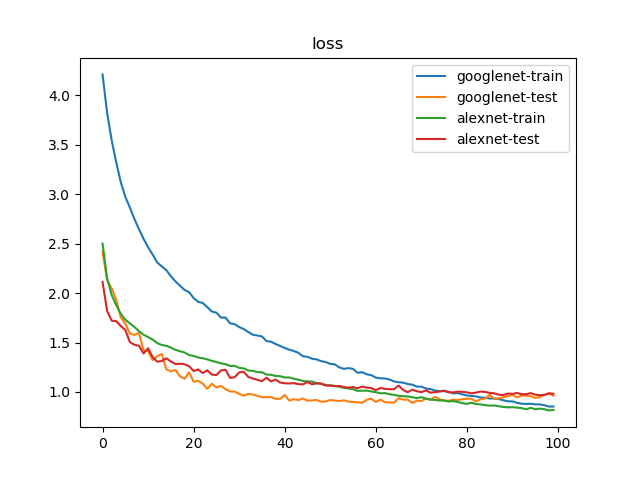
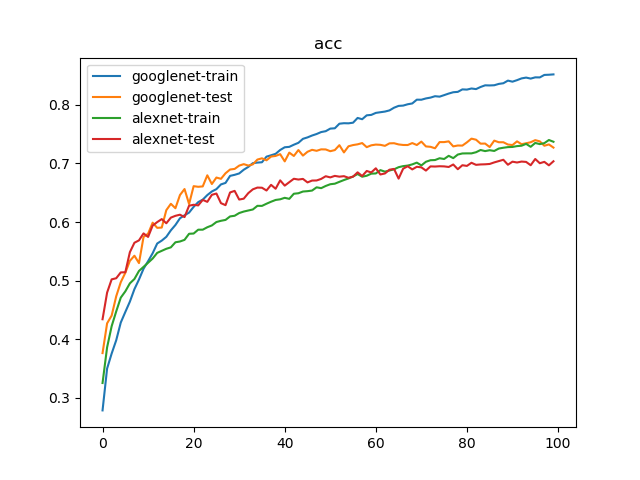
Appendix