论文Rethinking the Inception Architecture for Computer Vision对GoogLeNet和GoogleNet_BN的实现做了进一步的解释,同时提出了新的Inception模块和损失函数LSR(label-smoothing regularizer)
上一篇实现了Inception_v2架构,经过测试发现其损失收敛速度确实高于之前的GoogLeNet_BN。本文在此基础上实现Inception_v3架构
论文翻译地址:[译]Rethinking the Inception Architecture for Computer Vision
Inception_v2实现:[GoogLeNet]Inception_v2
发现一个在线可视化工具:Netscope CNN Analyzer,里面提供了Inception v3的可视化及详细参数:Inception v3
损失函数
交叉熵损失
计算每个类别属于每个类型的概率
\[ k ∈ {1 . . . K}: p(k|x) =\frac {exp(z_{k})}{\sum^{K}_{i=1} exp(z_{i})} \]
其中\(z_{i}\)表示输出值或者未归一化的对数概率。计算交叉熵损失如下:
\[ l = -\sum_{k=1}^{K} log(p(k))q(k) \]
最小化交叉熵相当于最大化正确标签的对数似然性。这里存在两个问题:
- 如果模型学会为每个训练示例分配全部概率给真值标签,它就不能保证泛化效果
- 它鼓励最大
logit和所有其他logit之间的差异变大,这与有界梯度\(\frac {∂l}{∂z_{k}}\)相结合,降低了模型的迁移能力
标签平滑正则化
论文提出了一种新的机制来正则化模型训练。考虑基于标签的分布\(u(k)\),其独立于训练样本\(x\),拥有一个平滑参数$ ε\(。对于带有真值标签\)y\(的训练样本,我们将标签分布\)q(k|x) = δ_{k,y}$替换为
\[ {q}'(k|x) = (1 - \epsilon)δ_{k,y} + \epsilon u(k) \]
将使用标签上的优先分布作为\(u(k)\)。在实验中使用均匀分布\(u(k) = 1/K\),实现如下:
\[ {q}'(k) = (1 - \epsilon)δ_{k,y} + \frac {\epsilon}{K} \]
这种真值标签分布的变化为标签平滑正则化(LSR)。LSR能够实现有效防止最大逻辑变得比所有其他逻辑大得多的预期目标
PyTorch
Inception_v3相比于Inception_v2,在模型架构上没有很大差别,仅仅对辅助分类器实现了BN,以及使用LSR来训练网络
在PyTorch实现中,取消了Inception_v2中最后两个全连接层使用的随机失活,同时使用LSR作为损失函数。具体实现参考zjZSTU/GoogLeNet
LSR实现如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
|
"""
@date: 2020/4/10 上午9:19
@file: label_smoothing_regularization.py
@author: zj
@description: 实现标签平滑正则化
"""
import torch
import torch.nn as nn
class LabelSmoothRegularizatoin(nn.Module):
def __init__(self, K, epsilon=0.1):
assert 0 <= epsilon < 1
super(LabelSmoothRegularizatoin, self).__init__()
self.criterion = nn.CrossEntropyLoss()
self.uk = 1.0 / K
self.epsilon = epsilon
def forward(self, outputs, targets):
return self.criterion(outputs, targets) * (1 - self.epsilon) + self.epsilon * self.uk
if __name__ == '__main__':
outputs = torch.randn((128, 10))
targets = torch.ones(128).long()
tmp = LabelSmoothRegularizatoin(10, epsilon=0.1)
loss = tmp.forward(outputs, targets)
print(loss)
|
训练
比对Inception_v2和Inception_v3,训练参数如下:
- 数据集:
PASCAL VOC 07+12,20类共40058个训练样本和12032个测试样本 - 批量大小:
128 - 损失函数:
LSR - 优化器:
Adam,学习率为1e-3 - 随步长衰减:每隔
8轮衰减4%,学习因子为0.96 - 迭代次数:
100轮
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
| {'train': 40058, 'test': 12032}
Epoch 0/99
----------
train Loss: 2.9042 Acc: 0.3335
test Loss: 2.0070 Acc: 0.4000
Epoch 1/99
----------
train Loss: 2.6089 Acc: 0.3695
test Loss: 1.9186 Acc: 0.4008
Epoch 2/99
----------
。。。
。。。
----------
train Loss: 0.1762 Acc: 0.9593
test Loss: 0.8700 Acc: 0.7944
Epoch 98/99
----------
train Loss: 0.1778 Acc: 0.9568
test Loss: 0.9174 Acc: 0.7817
Epoch 99/99
----------
train Loss: 0.1809 Acc: 0.9562
test Loss: 0.8547 Acc: 0.7862
Training complete in 309m 25s
Best test Acc: 0.794382
train inception_v3 done
Epoch 0/99
----------
train Loss: 3.0218 Acc: 0.3277
test Loss: 4.4148 Acc: 0.3464
Epoch 1/99
----------
train Loss: 2.7195 Acc: 0.3553
test Loss: 2.2528 Acc: 0.3896
Epoch 2/99
----------
。。。
。。。
----------
train Loss: 0.2697 Acc: 0.9337
test Loss: 1.1765 Acc: 0.7738
Epoch 98/99
----------
train Loss: 0.2649 Acc: 0.9368
test Loss: 0.8809 Acc: 0.7728
Epoch 99/99
----------
train Loss: 0.2668 Acc: 0.9353
test Loss: 1.2179 Acc: 0.7685
Training complete in 309m 33s
Best test Acc: 0.783577
train inception_v2 done
|
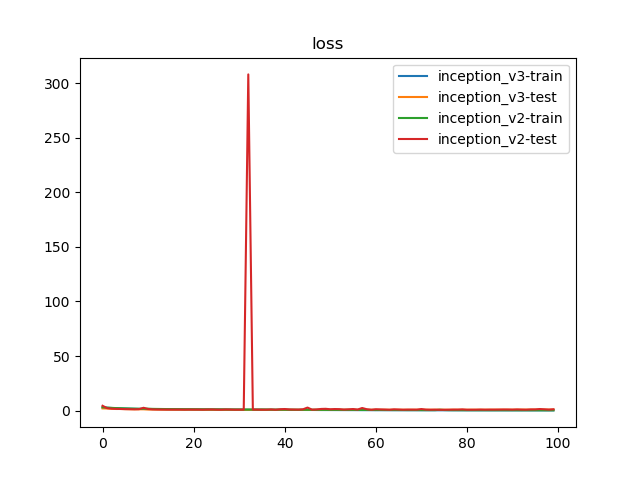
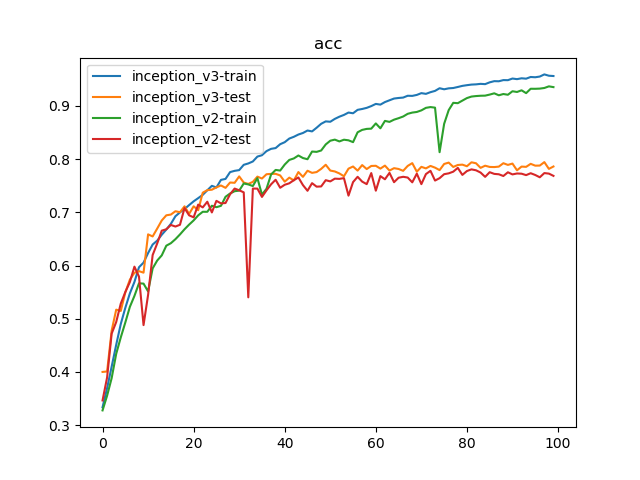
100轮迭代后,Inception_v2实现了78.36%的最好测试精度,Inception_v3实现了79.44%的最好测试精度
LSR确实启动了正则化的作用- 取消随机失活能够进一步加速批量归一化的收敛效果