神经网络实现-numpy
使用numpy实现神经网络模型
- 使用单层神经网络
OneNet实现逻辑或、逻辑与和逻辑非分类 - 使用
2层神经网络TwoNet实现逻辑异或分类 - 使用
3层神经网络ThreeNet实现iris数据集和mnist数据集分类
使用单层神经网络OneNet实现逻辑或、逻辑与和逻辑非分类
使用单层神经网络OneNet
- 输入层有
2个神经元 - 输出层有
1个神经元 - 评分函数是
sigmoid - 损失函数是交叉熵损失
OneNet就是逻辑回归模型
前向传播过程
所以分类概率是
损失值是
因为OneNet很特殊(类别不是0就是1),所以损失值可以用下式计算
反向传播过程
计算最终残差
因为
所以
因为OneNet是单层神经网络,所以仅有一个权重矩阵和偏置值
偏置向量需要考虑维数
进行权重更新时添加正则化项
numpy实现
1 | # -*- coding: utf-8 -*- |
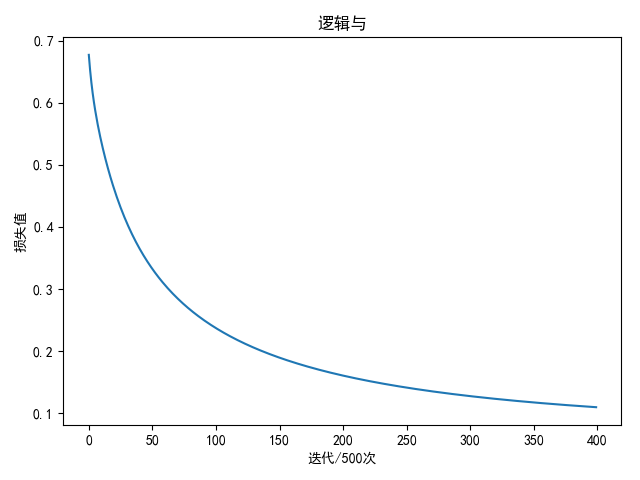
逻辑与
输入值与输出值
- (0,0) - 0
- (0,1) - 0
- (1,0) - 0
- (1,1) - 1
1 | input_array = np.array([[0, 0], [0, 1], [1, 0], [1, 1]]) |
参数如下:
1 | # 批量大小 |
进行2万轮迭代后
1 | weight: [[3.58627447 3.58664415] |
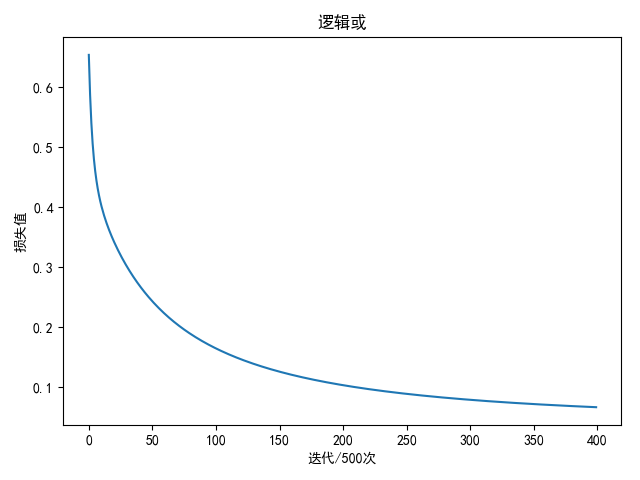
逻辑或
输入值与输出值
- (0,0) - 0
- (0,1) - 1
- (1,0) - 1
- (1,1) - 1
1 | input_array = np.array([[0, 0], [0, 1], [1, 0], [1, 1]]) |
参数如下:
1 | # 批量大小 |
进行2万轮迭代后
1 | weight: [[4.63629047] |
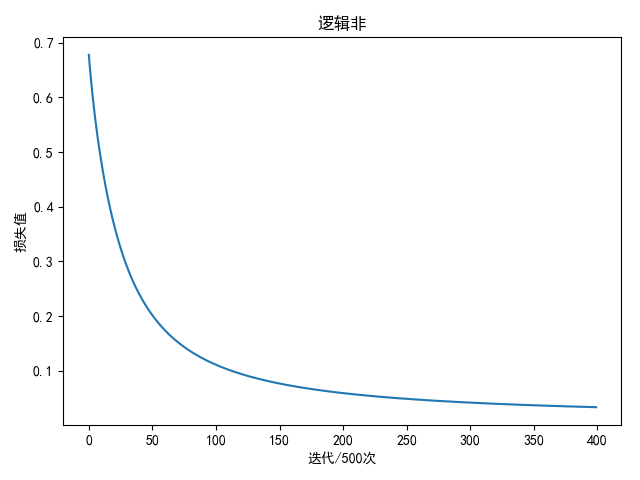
逻辑非
输入值与输出值
- 0
- 1
1 | input_array = np.array([[1], [0]]) |
参数如下:
1 | # 批量大小 |
进行2万轮迭代后
1 | weight: [[-6.79010254]] |
使用2层神经网络TwoNet实现逻辑异或分类
使用2层神经网络TwoNet
- 网络层数
- 批量数据
- 输入层神经元个数
- 隐藏层神经元个数
- 输出层神经元个数
- 激活函数是
relu - 评分函数是
softmax评分 - 损失函数是交叉熵损失平凡

前向传播过程
所以分类概率是
其中
损失值是
反向传播过程
输出层输入向量梯度
所以
对于输出层权重矩阵、偏置向量以及隐藏层输出向量
输出层权重矩阵
输出层偏置向量
隐藏层输出向量
对于隐藏层输入向量
对于隐藏层权重矩阵和偏置值
输出层权重矩阵
输出层偏置向量
numpy实现
1 | # -*- coding: utf-8 -*- |
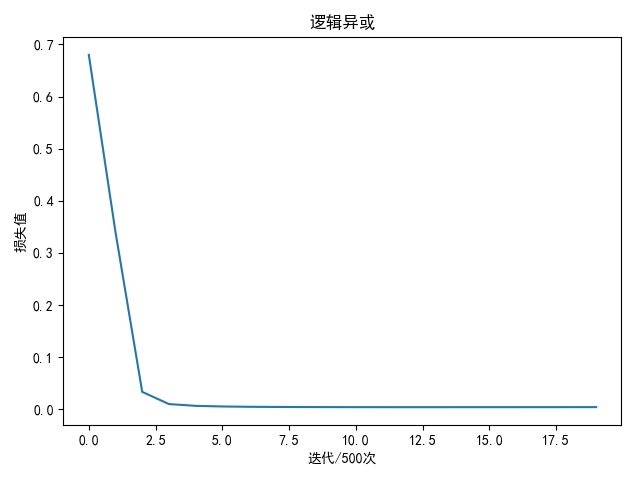
逻辑异或
输入值与输出值
- (0,0) - 0
- (0,1) - 1
- (1,0) - 1
- (1,1) - 0
1 | input_array = np.array([[0, 0], [0, 1], [1, 0], [1, 1]]) |
参数如下:
1 | # 批量大小 |
进行1万轮迭代后
1 | weight: [[-1.39091559 0.26154732 -0.90273461 1.66258303 1.63181952 -1.61815551] |
使用3层神经网络ThreeNet实现iris数据集和mnist数据集分类
使用3层神经网络ThreeNet
- 网络层数
- 批量数据
- 输入层神经元个数
- 第一个隐藏层神经元个数
- 第二个隐藏层神经元个数
- 输出层神经元个数
- 激活函数是
relu - 评分函数是
softmax评分 - 损失函数是交叉熵损失平凡
前向传播过程
所以分类概率是
其中
损失值是
反向传播过程
输出层输入向量梯度
对于输出层权重矩阵、偏置向量以及第二个隐藏层输出向量
对于第二个隐藏层输入向量
对于第二个隐藏层权重矩阵、偏置向量和第一个隐藏层输出向量
对于第一个隐藏层输入向量
对于第一个隐藏层权重矩阵和偏置向量
numpy实现
1 | class ThreeNet(object): |
iris数据集
分类鸢尾(iris)数据集,下载地址:iris
共4个变量:
SepalLengthCm- 花萼长度SepalWidthCm- 花萼宽度PetalLengthCm- 花瓣长度PetalWidthCm- 花瓣宽度
以及3个类别:
Iris-setosaIris-versicolorIris-virginica
网络和训练参数如下:
1 | # 批量大小 |
完整代码如下:
1 | # -*- coding: utf-8 -*- |
训练1万次结果如下:
1 | best train accuracy: 98.33 % |
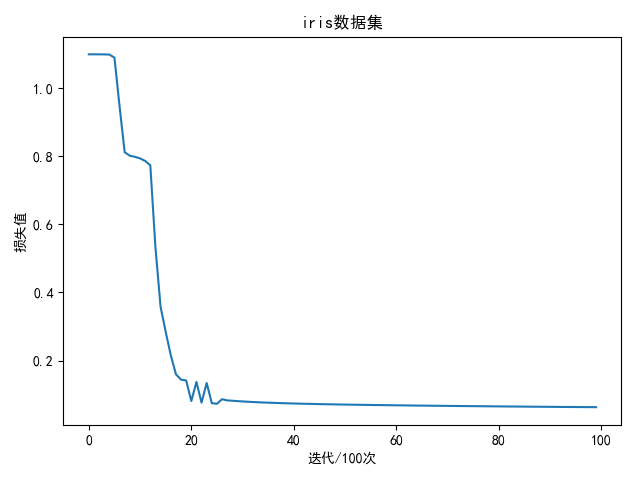
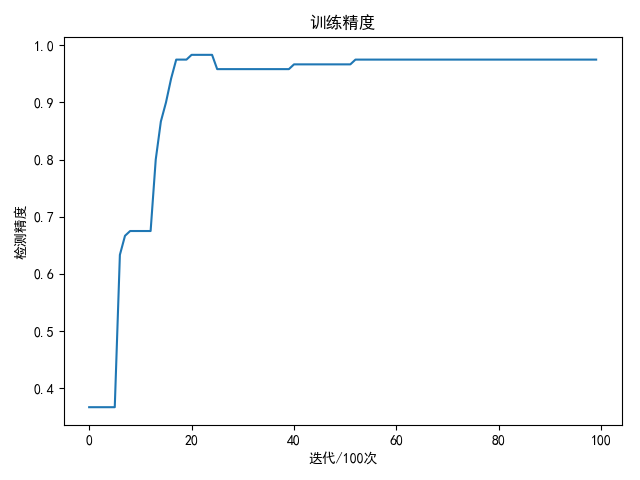
| softmax回归 | 神经网络 | |
|---|---|---|
| iris | 96.67% | 98.33% |
mnist数据集
mnist数据集是手写数字数据集,共有共有60000张训练图像和10000张测试图像,分别表示数字0-9
数据集的下载和解压参考:Python MNIST解压
网络和训练参数如下:
1 | # 批量大小 |
完整代码如下:
1 | # -*- coding: utf-8 -*- |
训练200次结果如下:
1 | best train accuracy: 100.00 % |
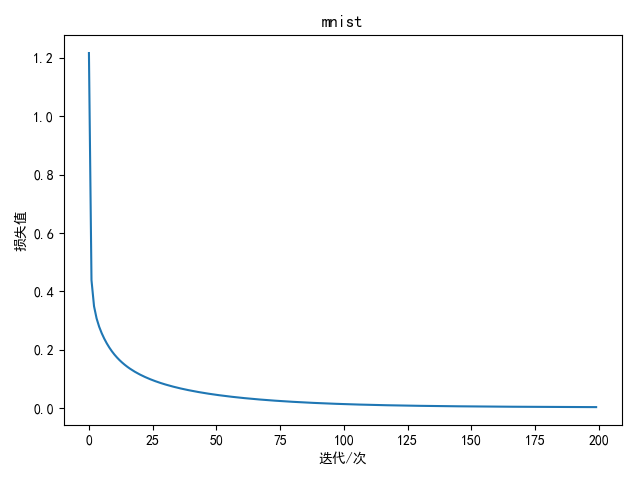
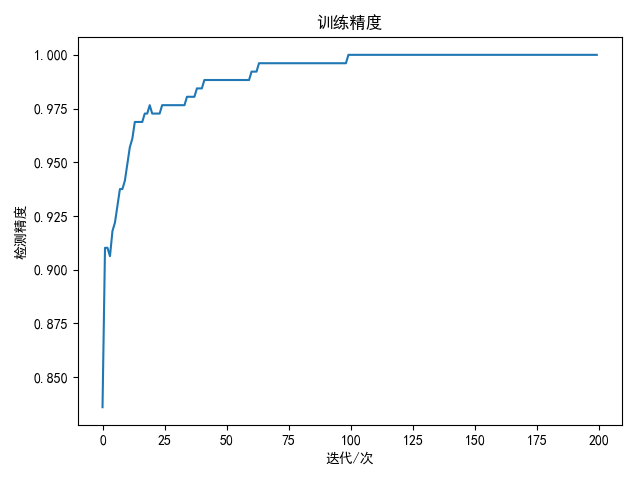
| softmax回归 | 神经网络 | |
|---|---|---|
| mnist | 92.15% | 97.92% |
Gitalk 加载中 ...