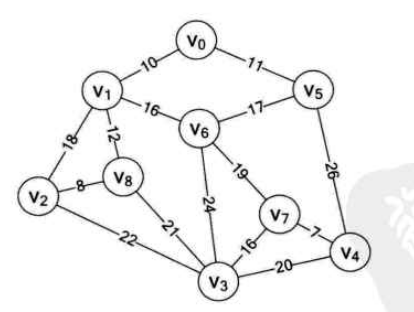
// 最先添加顶点0到MST中 // adjvex赋值为边的另一个顶点值, 如果顶点已在MST中,指定下标赋值为-1 int begin_vex = 0; adjvex[begin_vex] = 0; lowcost[begin_vex] = -1; for (i = 1; i < G.numVertexes; i++) { lowcost[i] = G.arcs[0][i]; adjvex[i] = 0; }
int weight = 0; // 遍历n-1轮,得到另外的顶点 for (i = 1; i < G.numVertexes; i++) { min = GINFINITY; // 遍历n-1次,搜索最小权值边 j = 1, k = 0; while (j < G.numVertexes) { if (lowcost[j] != -1and lowcost[j] < min) { min = lowcost[j]; k = j; } j++; }
// 初始化 for (i = 0; i < G.numVertexes; i++) { lowcost[i] = GINFINITY; adjvex[i] = 0; }
// 默认添加顶点0到MST // adjvex赋值为边的另一个顶点值, 如果顶点已在MST中,指定下标赋值为-1 int begin_index = 0; adjvex[begin_index] = 0; lowcost[begin_index] = -1; e = G.adjList[begin_index].firstEdge; while (e != nullptr) { lowcost[e->adjvex] = e->weight; adjvex[e->adjvex] = 0;
e = e->next; }
int weight = 0; // 遍历n-1轮,得到另外的顶点 for (i = 1; i < G.numVertexes; i++) { min = GINFINITY; // 遍历n-1次,搜索最小权值边 j = 1, k = 0; while (j < G.numVertexes) { if (lowcost[j] != -1 and lowcost[j] < min) { min = lowcost[j]; k = j; } j++; }
// 权值边存储结构 typedefstruct { intbegin; intend; int weight; } Edge;
voidAdjacencyMatrixUndirectedGraph::MiniSpanTree_Kruskal(MGraph G){ int i, j, k, n, m; std::array<Edge, MAXEDGE> edges = {}; // 保存最小生成树,数组下标表示一个顶点,赋值表示另一个顶点 std::array<int, MAXEDGE> parent = {};
// 将边集赋值给edges k = 0; for (i = 0; i < G.numVertexes; i++) { for (j = i + 1; j < G.numVertexes; j++) { if (G.arcs[i][j] != GINFINITY) { Edge edge; edge.begin = i; edge.end = j; edge.weight = G.arcs[i][j];
voidAdjacencyTableUndirectedGraph::MiniSpanTree_Kruskal(GraphAdjList G){ int i, j, k, n, m; EdgeNode *e; std::array<Edge, MAXEDGE> edges = {}; // 保存最小生成树,数组下标表示一个顶点,赋值表示另一个顶点 int parent[MAXVEX] = {};
// 将边集赋值给edges k = 0; for (i = 0; i < G.numVertexes; i++) { e = G.adjList[i].firstEdge;
while (e != nullptr) { if (e->adjvex > i) { Edge edge; edge.begin = i; edge.end = e->adjvex; edge.weight = e->weight;
未找到相关的 Issues 进行评论
请联系 @zjykzj 初始化创建